Running Errata for Why Machines Learn: The Elegant Math Behind Modern AI
While I have tried my level best to ensure Why Machines Learn is free of errors, books of this nature and size (at nearly 500 pages) invariably have some, whether it’s to do with formatting of math symbols (erroneous formatting can alter what a symbol means) or an error in the formulation or explanation of the math itself. This errata will also contain updates about any factual errors in the book. Please note that errors are being fixed in reprints of the print version soon as possible. The Kindle version should also be updated soon as there’s a reprint.
Use the form below to submit any error you have found:
Errata
Hardcover (1st printing)
Page 55: “…, where the logic gate outputs a 1 if both the inputs are the same, and 0 otherwise.” This should read: “…, where the logic gate outputs a 0 if both inputs are the same, and 1 otherwise.”
Page 59: In the equation for y (middle of the page), w should be replaced by w*
Page 87: “error(e)” should read: “error, e”
Page 89: The symbol for gradient should be an upside down triangle, not an upright triangle as shown.
Page 109/110: The expectation value calculated on page 110 was done using certain empirical probabilities calculated using a different instance of the experiment than the one depicted in the illustration on page 109. This happened because of a last-minute change to illustration, but not the main text. This does not change the central idea of using empirical probabilities that you get from an experiment. If you were use the values shown in the illustration, you’d also get an expectation value close to 3.
Page 119: “Take the derivative of the function. In the case of MLE, the derivative is taken with respect to x, the data.” This should read: “Take the derivative of the function. In the case of MLE, the derivative is taken with respect to the parameter theta.” (An additional note: the form of the function being analyzed will differ for MLE and MAP. But in both cases, the derivate is taken with respect to “theta”, which signifies the set of parameters that characterize the probability distribution.)
Page 209: “See a pointer to an excellent exposition of the math” should read “See Notes for a pointer to an excellent exposition of the math."
Page 283: “If a network requires more than one weight matrix (one for the output layer and one for each hidden layer), then it’s called a deep neural network: the greater the number of hidden layers, the deeper the network.” This should read: “If a network requires more than two weight matrices (one for the output layer and one for each hidden layer), then it’s called a deep neural network: the greater the number of hidden layers, the deeper the network.”
Page 377: “That year, Stanford University professor Fei-Fei Li and her students presented a paper at the first Computer Vision and Pattern Recognition (CVPR) conference.” Delete the word “first” before “Computer Vision and Pattern recognition (CVPR) conference”. CVPR was held first in the 1983.
Page 388: “For example, you could use a k-nearest neighbor algorithm (chapter 5) k.” has a superfluous 'k’ at the end of the sentence. It should read “For example, you could use a k-nearest neighbor algorithm (chapter 5).”
The above errors have been fixed in the 2nd printing (US hardcover) and in Kindle editions.
Page 189: I’m using the programmer’s way of equating the LHS and RHS of the equation: h1 = h1 - E(h), where “=” really means that you evaluate the RHS of the equation and assign it to the LHS of the equation. Same goes for the use of “=” on page 190 and 191, when adding the squares of the mean-corrected heights and weights.
Page 197: “Taking the dot product of Wr and X gives us T.” This should read, “Taking the dot product of X and Wr gives us T.” The order is correct in the equation that follows, the English language description had the order of X and Wr reversed.
Page 216: ‘Read that as “delta f of x y”’ This should read: ‘Read that as “the gradient of f’”
Page 228: The arrow symbol is used interchangeably with the “=” sign, when I’m discussing the mapping of K(x, y) to phi(x).phi(y). Please read the arrow symbol to mean equal to in this case. I picked up this notation from university lectures, and while it seems obvious, it also might be confusing to the discerning reader with a keen eye for notation. Same goes the use of the arrow symbol on page 230 (2nd paragraph).
Page 248: “adjacent pairs” should read: “pairs”
Page 259: The two vectors being multiplied at the very end of the page: the symbol in between should represent an outer product. See: https://en.wikipedia.org/wiki/Outer_product
Page 260: In the equation for the weight matrix, W, the symbol for the identity matrix, I, should be in bold.
Page 274, 274: The equation at the end of the page 274, depicting the difference in energy between Enew and Eold, should have the symbol for “delta” [an upright triangle] instead of the symbol for “gradient” [an upside-down triangle]. There are two other occurrences of this on page 275, before it’s used correctly.
Page 318: Again, the update rule uses notation that would be familiar to programmers: The LHS of the equation is being assigned to the value being computed on the RHS of the equation. Please read it as such. Otherwise the equation only holds (in the true mathematical sense) for delta-W or delta-b equal to zero!
Page 322: “Our algorithm iterates over all the test data until the loss…” should read “Our algorithm iterates over all the training data until the loss…” (test should be training)
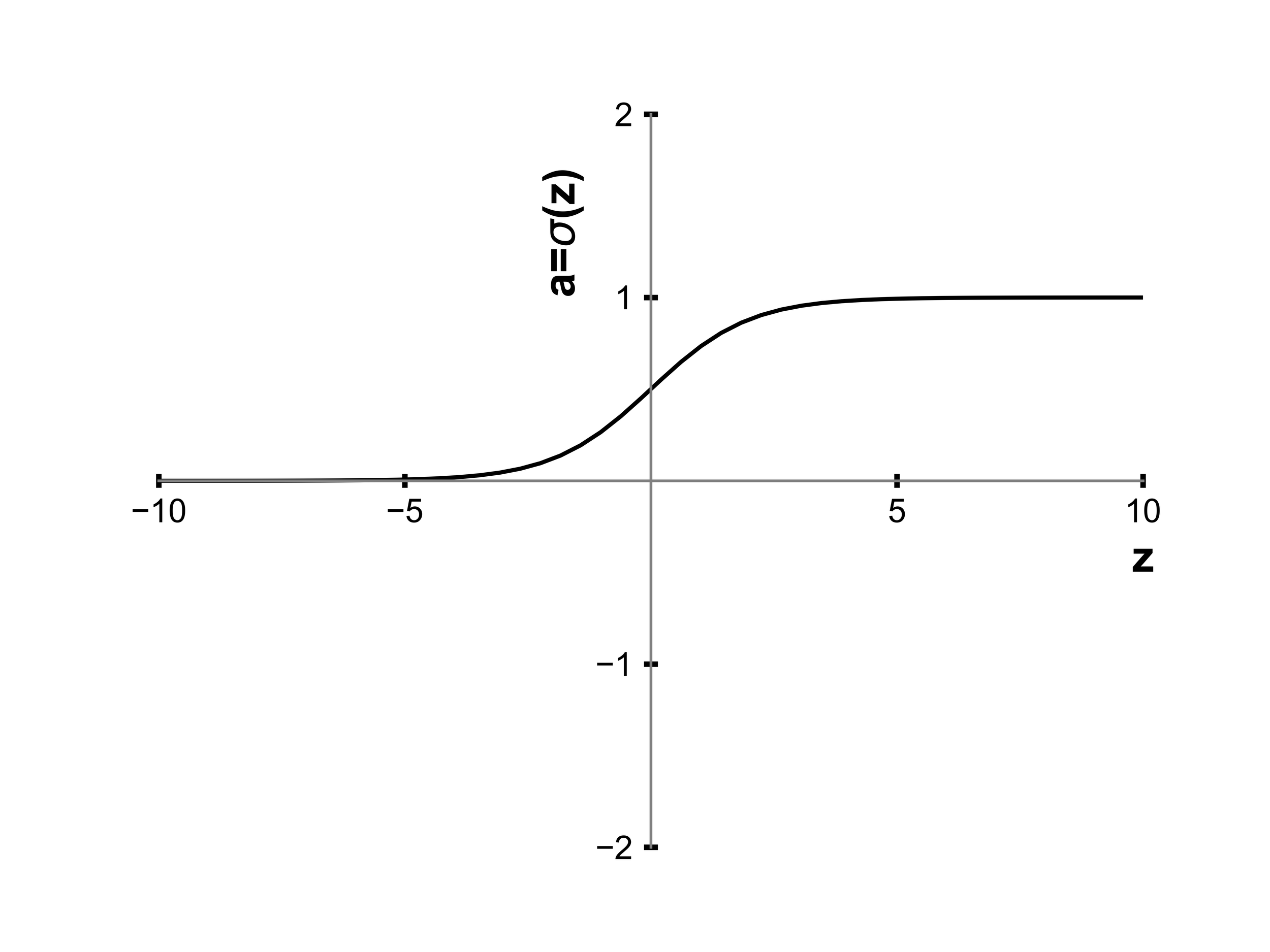
Page 327: The graph depicting the sigmoid function has got the wrong markings on the x-axis. Here’s the correct markings:
Page 361: Technically, in deep learning, the term convolution as it applies to images is used loosely. In fact, the procedure shown in the chapter is something called a cross-correlation. If you had to do a convolution, you’d flip the kernel both horizontally and vertically before doing the operation shown in the chapter. I’ve used the term convolution, instead of cross-correlation, to be consistent with the general usage in deep learning literature.
Page 373: “Fine- tuning, or finding the right values for, the hyperparameters is an art unto itself” should read “Tuning, or finding the right values for, the hyperparameters is an art unto itself.”
Page 406: “But by 2011, when AlexNet won the ImageNet competition.” 2011 should be 2012
Page 407: “The function is not convex, meaning it doesn’t have one global minimum toward which you can descend.” In this sentence, modify “doesn’t have one global minimum” to “doesn’t have just the one global minimum.”
Page 407: ‘So far, no one knows if the landscape has a global minimum or just lots of good local minima (where “good” means loss is acceptably low).’ Should read: ‘So far, no one knows if the landscape has a “best” global minimum or also lots of good local minima (where “good” means loss is acceptably low).’